Détection de fraudes dans les cartes bancaires
Problematique:¶
L'objectif de ce projet est la classification desequilibree des donnees, Ce déséquilibre de classe augmente nettement la difficulté de l’apprentissage par l’algorithme de classification. En effet, l’algorithme n’a que peu d’exemples de la classe minoritaire sur lesquels apprendre. Il est donc biaisé vers la population des négatifs et produit des prédictions potentiellement moins robustes qu’en l’absence de déséquilibre.
[1] "Occurence des fraudes"
0 1
284315 492
Analyse statistique des données¶
Dans notre cas, la classification déséquilibrée est un problème de classification dans lequel une classe est sous-représentée par rapport aux autres. Le cas classique est un problème à deux classes, une majoritaire à 99% et une minoritaire à 1%.
La matrice de corrélation nous montre que la corrélation entre les variables V1 à V28 est
très négligeable, ce qui est prévisible puisque ces variables proviennent d’une PCA et
donc les composantes doivent forcément être décorrélées.
Cependant, il existe une corrélation entre les variables Amount et
Class qui pourra nous permettre peut-être de faciliter la classification
plus tard, pour deviner si une transaction est frauduleuse ou non, vu que le montant
d’une transaction peut être un facteur important pour décider si une transaction est
frauduleuse ou pas.
Modeles de régression logistique¶
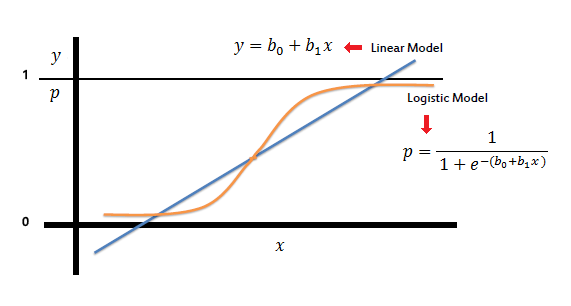
L'algorithme de régression logistique va mesurer la relation entre le "Label" Y et les "Caractéristiques" X en estimant les probabilités à l'aide d'une fonction logistique appelée fonction sigmoid. C’est la fonction représentée sur la première figure et qui a pour but de séparer les transactions frauduleuses de celles non frauduleuses.
On travaillera tout d'abord sur l'integralite de nos donnees.
Dans tous les modeles suivants, On va séparer notre jeu de données données en 2 groupes : un groupe de training et un groupe de test. et on effectue la regression avec un seuil de décision à 0.5.
1) Integralite des donnees¶
Nombre d'occurences du training set
0 1
181953 323
Modele de regression logistique
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 45483 33
1 6 47
Accuracy : 0.9991
On remarque que l'accuracy de notre modele est de 99,9%. A premiere vue, le modele semble efficace mais dans le cas du déséquilibre de classes, l’exactitude peut être trompeuse. Avec un jeu de données de deux classes, où la première classe représente 99% des données, si le classifieur prédit que chaque exemple appartient à la première classe, l’exactitude sera de 99%, mais ce classifieur est inutile dans la pratique
2) UpSampling avec duplication¶
L'upsampling ou le sur-échantillonnage aléatoire consiste à compléter les données de formation par des copies multiples de certaines d’instances de la classe minoritaire.
[1] "Occurence des fraudes"
0 1
284315 284315
On voit bien que nos données sont devenus équilibrées apres avoir ajouté plusieurs copies des transactions frauduleuses.
On effectue alors la regression logistique
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 44547 3594
1 943 41896
Balanced Accuracy : 0.9501
On obtient une balanced accuracy de 95% , mais avec cette methode on risque d'avoir un overfitting pour les transactions frauduleuses.
3)Upsamling with SMOTE method¶
Pour dépasser l'inconvénient imposé par un upsamling normal, la méthode Smote (Synthetic Minority Oversampling Technique) peut être utilisé. L’idée de SMOTE est d’augmenter le rappel pour la classe minoritaire en générant des individus synthétiques sur les segments entre éléments proches de la classe minoritaire.
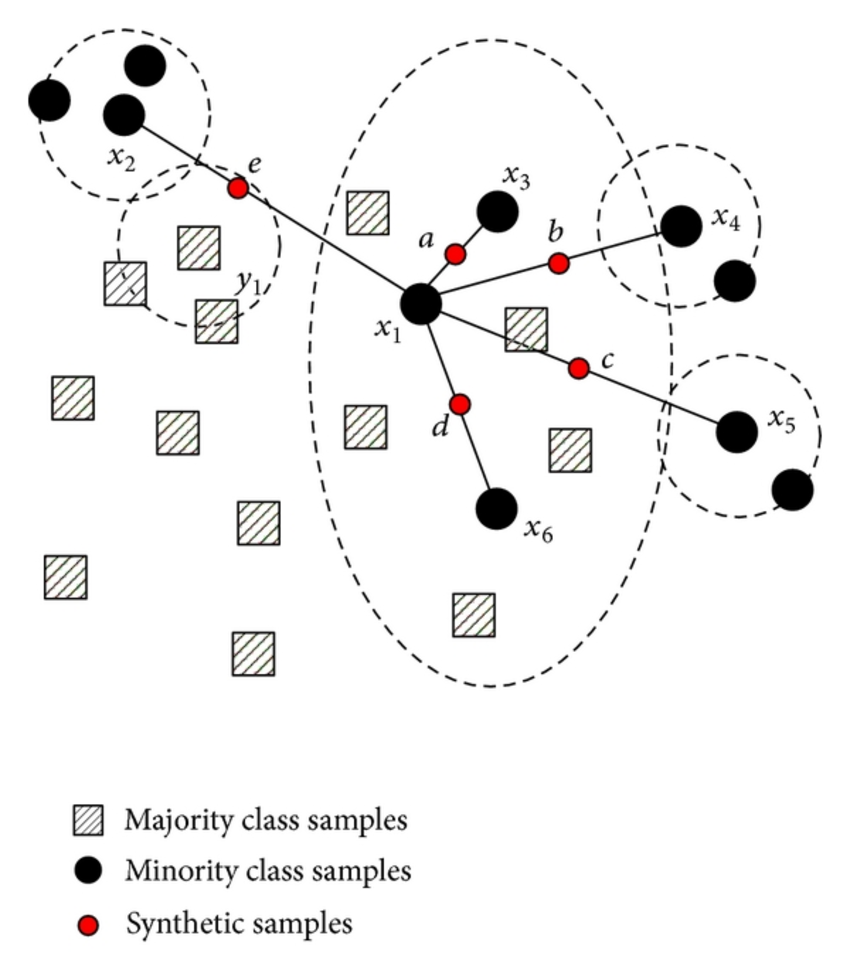
[1] "Occurence des fraudes"
0 1
283884 284376
On voit bien qu'on a generer autant de transactions frauduleuse que celles non frauduleuses.
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 44378 3406
1 1040 42096
Balanced Accuracy : 0.9511
Le modèle de regression est devenu plus efficace avec une balanced accuracy de 95,11%.
Mais ce modèle peut entrainer des erreurs, surtout que dans le domaine bancaire, on travaille avec des données sensible pour detecter les fraudes. Donc on ne peut pas se permettre de générer des données ( ~240000 transactions frauduleuses) pour modéliser la regression logistique.
4) Regression logistique pondérée¶
Dans la plupart des modèles de Machine learning, ils acceptent un paramètre
weight. Il sert à appliquer un coût inversement proportionnel au
déséquilibre de classe. Visuellement, cela permet de débiaiser le modèle vers la classe
minoritaire comme illustré ci-dessous où la frontière de décision d’un SVM à noyau
linéaire est translatée vers la classe minoritaire.

Dans notre cas, on prend notre poids comme le quotient de la somme des transactions non frauduleuses sur la somme des transactions frauduleuses. On obtient:
weight= 577
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 45490 0
1 0 78
Accuracy : 1
95% CI : (0.9999, 1)
Apres entrainenment, on voit qu’on a obtenu une précision de 100%, la méthode de régression logistique pondérée est efficace et plus adaptée a notre problème!